-
大佬,互换个友链, 已添加您了
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
-
博主已经添加了名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
-
古德古德
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
} 名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
知了小站
不怕学问浅,就怕志气短。
搜索到
73
篇与
的结果
-
 Spring boot 使用 logback 自定义日志脱敏教程 前言在我们书写代码的时候,会书写许多日志代码,但是有些敏感数据是需要进行安全脱敏处理的。对于日志脱敏的方式有很多,常见的有① 使用 conversionRule 标签,继承 MessageConverter② 书写一个脱敏工具类,在打印日志的时候对特定特字段进行脱敏返回两种方式各有优缺点:第一种方式需要修改代码,不符合开闭原则。第二种方式,需要在日志方法的参数进行脱敏,对原生日志有入侵行为。自定义脱敏组件(slf4j + logback)一个项目在书写了很多打印日志的代码,但是后面有了脱敏需求,如果我们去手动改动代码,会花费大量时间。如果引入本组件,完成配置即可轻松完成脱敏。(仅需三步可轻松配置)一、自定义脱敏组件 - 脱敏效果演示二、自定义脱敏组件 - 使用方式1、引入Jar包依赖前提是你将Jar包打入本地仓库,Jar包地址见后文。<dependency> <groupId>pers.liuchengyin</groupId> <artifactId>logback-desensitization</artifactId> <version>1.0.0</version> </dependency>2、替换日志文件配置类(logback.xml)日志打印方式都只需要替换成脱敏的类即可,如果你的业务不需要,则无需替换。① ConsoleAppender - 控制台脱敏// 原类 ch.qos.logback.core.ConsoleAppender // 替换类 pers.liuchengyin.logbackadvice.LcyConsoleAppender② RollingFileAppender - 滚动文件// 原类 ch.qos.logback.core.rolling.RollingFileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyRollingFileAppender③ FileAppender - 文件// 原类 ch.qos.logback.core.FileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyFileAppender替换示例:<property name="CONSOLE_LOG_PATTERN" value="%yellow(%date{yyyy-MM-dd HH:mm:ss}) |%highlight(%-5level) |%blue(%thread) |%blue(%file:%line) |%green(%logger) |%cyan(%msg%n)"/> <!-- ConsoleAppender 控制台输出日志 --> <appender name="CONSOLE" class="pers.liuchengyin.logbackadvice.LcyConsoleAppender"> <encoder> <pattern> ${CONSOLE_LOG_PATTERN} </pattern> </encoder> </appender>3、添加脱敏配置文件(logback-desensitize.yml)该配置文件应该放在 resources 文件下三、自定义脱敏组件 - 脱敏规范1、支持数据类型八大基本类型及其包装类型、Map、List、业务里的Pojo对象、List<业务里的Pojo对象>、JSON字符串。注:在配置文件中配置的时候,只需要配置对象里的属性值就行。2、不支持的数据类型List<八大基本类型及包装类型>,因为不知道脱敏的数据源具体是哪一个。3、匹配规则key + 分割符 + value,目前仅支持冒号 (:) 和等号 (=),示例如下:log.info("your email:{}, your phone:{}", "123456789@qq.com","15310763497"); log.info("your email={}, your cellphone={}", "123456789@qq.com","15310763497");key:定义了对应需要脱敏的关键字,如上诉的 email、phone 等以及业务对象中的字段、Map 中的 Key、JSON 中的 Keyvalue:需要脱敏的值,如上诉的 123456789@qq.com、153107634974、日志规范建议书写日志的时候尽量规范,对于key为中文的是没有办法脱敏的,规范程度可以见脱敏效果演示里的代码。四、logback-desensitize.yml配置说明# 日志脱敏 log-desensitize: # 是否忽略大小写匹配,默认为true ignore: true # 是否开启脱敏,默认为false open: true # pattern下的key/value为固定脱敏规则 pattern: # 邮箱 - @前第4-7位脱敏 email: "@>(4,7)" # qq邮箱 - @后1-3位脱敏 qqemail: "@<(1,3)" # 姓名 - 姓脱敏,如*杰伦 name: 1,1 # 密码 - 所有需要完全脱敏的都可以使用内置的password password: password patterns: # 身份证号,key后面的字段都可以匹配以下规则(用逗号分隔) - key: identity,idcard # 定义规则的标识 custom: # defaultRegex表示使用组件内置的规则:identity表示身份证号 - 内置的18/15位 - defaultRegex: identity position: 9,13 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 9,10 # 电话号码,key后面的字段都可以匹配以下规则(用逗号分隔) - key: phone,cellphone,mobile custom: # 手机号 - 内置的11位手机匹配规则 - defaultRegex: phone position: 4,7 # 自定义正则匹配表达式:座机号(带区号,号码七位|八位) - customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" # -后面的1-4位脱敏 position: "-<(1,4)" # 自定义正则匹配表达式:座机号(不带区号) - customRegex: "^[0-9]{7,8}" position: 3,5 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 1,3 # 这种方式不太推荐 - 一旦匹配不上,就不会脱敏 - key: localMobile custom: customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" position: 1,3上面这个配置是相对完整的,一定要严格遵守层级配置格式。自定义脱敏支持的方式1、key:value的方式phone:4,7,表示 phone 属性的 4-7 位进行脱敏原始数据:13610357861脱敏后:136**78612、以符号作为起始、结束节点作为脱敏标志email:"@>(4,7)",@ 为脱敏标志,> 表示其为结束节点,< 表示其为开始节点。即 @> 表示对 @ 之前的进行脱敏,@< 表示对 @ 之后的进行脱敏。这个示例就是 @ 前的数据的第 4-7 位进行脱敏。注意:这种规则里的双引号、括号不能省略,其次 : 和 = 不能作为标志符号,因为和匹配规则有冲突。原始数据:123456789@qq.com"@>(4,7)"脱敏后:123**89@qq.com"@<(1,3)"脱敏后:123456789@*com3、自定义正则脱敏patterns: # 手机号 - key: phone,mobile custom: # 手机号的正则 - customRegex: "^1[0-9]{10}" # 脱敏范围 position: 4,7customRegex:正则表达式,如果符合该表达式,则使用其对应的脱敏规则 (position)4、一个字段,根据多种值含义进行自定义脱敏比如说,username 字段的值可以是手机号、也可以是邮箱,这个值动态改变的,前面几种方式都没办法解决,可以使用该方式。patterns: - key: username custom: # 手机号 - 11位 - defaultRegex: phone position : 4,7 # 邮箱 - @ - defaultRegex: email position : "@>(3,12)" # 身份证 - 15/18位 - defaultRegex: identity position : 1,3 # 自定义正则 - customRegex: "^1[0-9]{10}" position : 1,3 # 都匹配不到时,按照这种规则来 - defaultRegex: other position : 1,3注意:上面示例中匹配规则里的 双引号和括号 都不能省略该组件内置四种匹配规则:手机号、身份证号、邮箱、other(其他匹配不到时用的),内置一种脱敏方式:password,表示完全脱敏,可用于 pattren 下的。注:当pattern和patterns下的key有重复的时候,只会使用pattern下指定的方式进行脱敏。Jar包地址和源码地址Jar包Github地址 - logback-desensitization-1.0.0.jar Github地址: Logback和slf4j的日志脱敏组件Demo Gitee地址: Logback和slf4j的日志脱敏组件DemoJar包打入Maven本地仓库的方式1、下载Jar包,放在一个文件夹里2、在这个文件夹里打开cmd(打开cmd,进入到这个文件夹)3、执行命令(前提保证maven配置正常,使用mvn -v命令查看是否正常,如果显示版本号表示正常)mvn install:install-file -DgroupId=pers.liuchengyin -DartifactId=logback-desensitization -Dversion=1.0.0 -Dpackaging=jar -Dfile=logback-desensitization-1.0.0.jar命令说明: -DgroupId 表示jar对应的groupId <groupId>pers.liuchengyin</groupId> -DartifactId: 表示jar对应的artifactId <artifactId>logback-desensitization</artifactId> -Dversion 表示jar对应的 version <version>1.0.0</version>原文作者: 九月清晨柳成荫 原文地址:https://blog.csdn.net/qq_40885085/article/details/113385261?spm=1001.2014.3001.5501
Spring boot 使用 logback 自定义日志脱敏教程 前言在我们书写代码的时候,会书写许多日志代码,但是有些敏感数据是需要进行安全脱敏处理的。对于日志脱敏的方式有很多,常见的有① 使用 conversionRule 标签,继承 MessageConverter② 书写一个脱敏工具类,在打印日志的时候对特定特字段进行脱敏返回两种方式各有优缺点:第一种方式需要修改代码,不符合开闭原则。第二种方式,需要在日志方法的参数进行脱敏,对原生日志有入侵行为。自定义脱敏组件(slf4j + logback)一个项目在书写了很多打印日志的代码,但是后面有了脱敏需求,如果我们去手动改动代码,会花费大量时间。如果引入本组件,完成配置即可轻松完成脱敏。(仅需三步可轻松配置)一、自定义脱敏组件 - 脱敏效果演示二、自定义脱敏组件 - 使用方式1、引入Jar包依赖前提是你将Jar包打入本地仓库,Jar包地址见后文。<dependency> <groupId>pers.liuchengyin</groupId> <artifactId>logback-desensitization</artifactId> <version>1.0.0</version> </dependency>2、替换日志文件配置类(logback.xml)日志打印方式都只需要替换成脱敏的类即可,如果你的业务不需要,则无需替换。① ConsoleAppender - 控制台脱敏// 原类 ch.qos.logback.core.ConsoleAppender // 替换类 pers.liuchengyin.logbackadvice.LcyConsoleAppender② RollingFileAppender - 滚动文件// 原类 ch.qos.logback.core.rolling.RollingFileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyRollingFileAppender③ FileAppender - 文件// 原类 ch.qos.logback.core.FileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyFileAppender替换示例:<property name="CONSOLE_LOG_PATTERN" value="%yellow(%date{yyyy-MM-dd HH:mm:ss}) |%highlight(%-5level) |%blue(%thread) |%blue(%file:%line) |%green(%logger) |%cyan(%msg%n)"/> <!-- ConsoleAppender 控制台输出日志 --> <appender name="CONSOLE" class="pers.liuchengyin.logbackadvice.LcyConsoleAppender"> <encoder> <pattern> ${CONSOLE_LOG_PATTERN} </pattern> </encoder> </appender>3、添加脱敏配置文件(logback-desensitize.yml)该配置文件应该放在 resources 文件下三、自定义脱敏组件 - 脱敏规范1、支持数据类型八大基本类型及其包装类型、Map、List、业务里的Pojo对象、List<业务里的Pojo对象>、JSON字符串。注:在配置文件中配置的时候,只需要配置对象里的属性值就行。2、不支持的数据类型List<八大基本类型及包装类型>,因为不知道脱敏的数据源具体是哪一个。3、匹配规则key + 分割符 + value,目前仅支持冒号 (:) 和等号 (=),示例如下:log.info("your email:{}, your phone:{}", "123456789@qq.com","15310763497"); log.info("your email={}, your cellphone={}", "123456789@qq.com","15310763497");key:定义了对应需要脱敏的关键字,如上诉的 email、phone 等以及业务对象中的字段、Map 中的 Key、JSON 中的 Keyvalue:需要脱敏的值,如上诉的 123456789@qq.com、153107634974、日志规范建议书写日志的时候尽量规范,对于key为中文的是没有办法脱敏的,规范程度可以见脱敏效果演示里的代码。四、logback-desensitize.yml配置说明# 日志脱敏 log-desensitize: # 是否忽略大小写匹配,默认为true ignore: true # 是否开启脱敏,默认为false open: true # pattern下的key/value为固定脱敏规则 pattern: # 邮箱 - @前第4-7位脱敏 email: "@>(4,7)" # qq邮箱 - @后1-3位脱敏 qqemail: "@<(1,3)" # 姓名 - 姓脱敏,如*杰伦 name: 1,1 # 密码 - 所有需要完全脱敏的都可以使用内置的password password: password patterns: # 身份证号,key后面的字段都可以匹配以下规则(用逗号分隔) - key: identity,idcard # 定义规则的标识 custom: # defaultRegex表示使用组件内置的规则:identity表示身份证号 - 内置的18/15位 - defaultRegex: identity position: 9,13 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 9,10 # 电话号码,key后面的字段都可以匹配以下规则(用逗号分隔) - key: phone,cellphone,mobile custom: # 手机号 - 内置的11位手机匹配规则 - defaultRegex: phone position: 4,7 # 自定义正则匹配表达式:座机号(带区号,号码七位|八位) - customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" # -后面的1-4位脱敏 position: "-<(1,4)" # 自定义正则匹配表达式:座机号(不带区号) - customRegex: "^[0-9]{7,8}" position: 3,5 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 1,3 # 这种方式不太推荐 - 一旦匹配不上,就不会脱敏 - key: localMobile custom: customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" position: 1,3上面这个配置是相对完整的,一定要严格遵守层级配置格式。自定义脱敏支持的方式1、key:value的方式phone:4,7,表示 phone 属性的 4-7 位进行脱敏原始数据:13610357861脱敏后:136**78612、以符号作为起始、结束节点作为脱敏标志email:"@>(4,7)",@ 为脱敏标志,> 表示其为结束节点,< 表示其为开始节点。即 @> 表示对 @ 之前的进行脱敏,@< 表示对 @ 之后的进行脱敏。这个示例就是 @ 前的数据的第 4-7 位进行脱敏。注意:这种规则里的双引号、括号不能省略,其次 : 和 = 不能作为标志符号,因为和匹配规则有冲突。原始数据:123456789@qq.com"@>(4,7)"脱敏后:123**89@qq.com"@<(1,3)"脱敏后:123456789@*com3、自定义正则脱敏patterns: # 手机号 - key: phone,mobile custom: # 手机号的正则 - customRegex: "^1[0-9]{10}" # 脱敏范围 position: 4,7customRegex:正则表达式,如果符合该表达式,则使用其对应的脱敏规则 (position)4、一个字段,根据多种值含义进行自定义脱敏比如说,username 字段的值可以是手机号、也可以是邮箱,这个值动态改变的,前面几种方式都没办法解决,可以使用该方式。patterns: - key: username custom: # 手机号 - 11位 - defaultRegex: phone position : 4,7 # 邮箱 - @ - defaultRegex: email position : "@>(3,12)" # 身份证 - 15/18位 - defaultRegex: identity position : 1,3 # 自定义正则 - customRegex: "^1[0-9]{10}" position : 1,3 # 都匹配不到时,按照这种规则来 - defaultRegex: other position : 1,3注意:上面示例中匹配规则里的 双引号和括号 都不能省略该组件内置四种匹配规则:手机号、身份证号、邮箱、other(其他匹配不到时用的),内置一种脱敏方式:password,表示完全脱敏,可用于 pattren 下的。注:当pattern和patterns下的key有重复的时候,只会使用pattern下指定的方式进行脱敏。Jar包地址和源码地址Jar包Github地址 - logback-desensitization-1.0.0.jar Github地址: Logback和slf4j的日志脱敏组件Demo Gitee地址: Logback和slf4j的日志脱敏组件DemoJar包打入Maven本地仓库的方式1、下载Jar包,放在一个文件夹里2、在这个文件夹里打开cmd(打开cmd,进入到这个文件夹)3、执行命令(前提保证maven配置正常,使用mvn -v命令查看是否正常,如果显示版本号表示正常)mvn install:install-file -DgroupId=pers.liuchengyin -DartifactId=logback-desensitization -Dversion=1.0.0 -Dpackaging=jar -Dfile=logback-desensitization-1.0.0.jar命令说明: -DgroupId 表示jar对应的groupId <groupId>pers.liuchengyin</groupId> -DartifactId: 表示jar对应的artifactId <artifactId>logback-desensitization</artifactId> -Dversion 表示jar对应的 version <version>1.0.0</version>原文作者: 九月清晨柳成荫 原文地址:https://blog.csdn.net/qq_40885085/article/details/113385261?spm=1001.2014.3001.5501 -
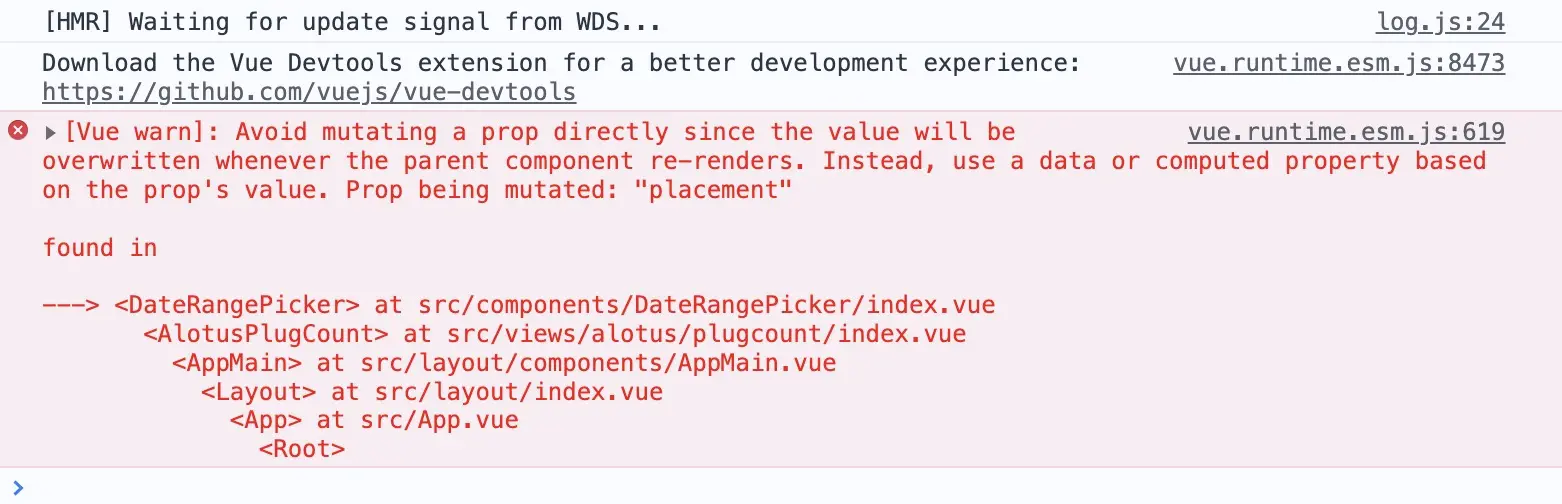
升级 element-ui 2.15.7 后遇到 el-date-picker 警告问题 近期把 element-ui 升级到了官网最新的 2.15.7 版本,无意间发现控制台出现了 Prop being mutated: "placement" 警告,完整警告:[Vue warn]: Avoid mutating a prop directly since the value will be overwritten whenever the parent component re-renders. Instead, use a data or computed property based on the prop's value. Prop being mutated: "placement"错误原因锁定组件,发现是 el-date-picker 组件抛出的警告。通过在 github 上搜索,最终找到了答案问题出在了这个 PR #21806 增加了 props placement 用来适应位置,但是之前的代码 created 时有给 placement 赋值。this.placement = PLACEMENT_MAP[this.align] || PLACEMENT_MAP.left; 说白了之前 placement 是 data 的对象,现在变成 props 了,然后修改就报错了解决方案想要解决这个问题,可以修改版本到 2.15.8npm uninstall element-ui npm install element-ui@2.15.8 -s解决方案来自:https://github.com/ElemeFE/element/issues/21905
-
Jpa进阶,使用 Specification 进行高级查询 前言上一篇文章主要讲了 Jpa 的简单使用,而在实际项目中并不能满足我们的需求。如对多张表的关联查询,以及查询时需要的各种条件,这个时候你可以使用自定义 SQL 语句,但是Jpa并不希望我们这么做,于是就有了一个扩展:使用 Specification 进行查询修改相应代码1、修改 User.class代码用的上一篇文章的,这里在 User 类中进行扩展,待会查询时会用到@Entity @Table(name = "user") public class User { //部分代码略 /** * 加上该注解,在保存该实体时,Jpa将为我们自动设置上创建时间 */ @CreationTimestamp private Timestamp createTime; /** * 加上该注解,在保存或者修改该实体时,Jpa将为我们自动创建时间或更新日期 */ @UpdateTimestamp private Timestamp updateTime; /** * 关联角色,测试多表查询 */ @ManyToOne @JoinColumn(name = "role_id") private Role role; //部分代码略 }2、新增Role.class@Entity @Table(name = "role") public class Role { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(unique = true,nullable = false) private String name; //get set略 }3、修改UserRepository要使用 Specification,需要继承 JpaSpecificationExecutor 接口,修改后的代码如下public interface UserRepo extends JpaRepository<User,Long>, JpaSpecificationExecutor { }4、查看 JpaSpecificationExecutor 源码Specification 是 Spring Data JPA 提供的一个查询规范,这里所有的操作都是围绕 Specification 来进行public interface JpaSpecificationExecutor<T> { Optional<T> findOne(@Nullable Specification<T> var1); List<T> findAll(@Nullable Specification<T> var1); Page<T> findAll(@Nullable Specification<T> var1, Pageable var2); List<T> findAll(@Nullable Specification<T> var1, Sort var2); long count(@Nullable Specification<T> var1); }封装查询Service我这里简单做了下简单封装,编写 UserQueryService.class@Service public class UserQueryService { @Autowired private UserRepo userRepo; /** * 分页加高级查询 */ public Page queryAll(User user, Pageable pageable , String roleName){ return userRepo.findAll(new UserSpec(user,roleName),pageable); } /** * 不分页 */ public List queryAll(User user){ return userRepo.findAll(new UserSpec(user)); } class UserSpec implements Specification<User>{ private User user; private String roleName; public UserSpec(User user){ this.user = user; } public UserSpec(User user,String roleName){ this.user = user; this.roleName = roleName; } @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) { List<Predicate> list = new ArrayList<Predicate>(); /** * 左连接,关联查询 */ Join<Role,User> join = root.join("role",JoinType.LEFT); if(!StringUtils.isEmpty(user.getId())){ /** * 相等 */ list.add(cb.equal(root.get("id").as(Long.class),user.getId())); } if(!StringUtils.isEmpty(user.getUsername())){ /** * 模糊 */ list.add(cb.like(root.get("username").as(String.class),"%"+user.getUsername()+"%")); } if(!StringUtils.isEmpty(roleName)){ /** * 这里的join.get("name"),就是对应的Role.class里面的name */ list.add(cb.like(join.get("name").as(String.class),"%"+roleName+"%")); } if(!StringUtils.isEmpty(user.getCreateTime())){ /** * 大于等于 */ list.add(cb.greaterThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getCreateTime())); } if(!StringUtils.isEmpty(user.getUpdateTime())){ /** * 小于等于 */ list.add(cb.lessThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getUpdateTime())); } Predicate[] p = new Predicate[list.size()]; return cb.and(list.toArray(p)); } } }查询测试1、新增测试数据 @Test public void test3() { /** * 新增角色 */ Role role = new Role(); role.setName("测试角色"); role = roleRepo.save(role); /** * 新增并绑定角色 */ User user = new User("小李",20,"男",role); User user1 = new User("小花",21,"女",role); userRepo.save(user); userRepo.save(user1); }查看数据都已经新增成功了,并且 createTime 和 updateTime 也帮我们加上了2、简单查询 @Test public void Test4(){ /** * 添加查询数据,模糊查询用户名 */ User user = new User(); user.setUsername("花"); List<User> users = userQueryService.queryAll(user); users.forEach(user1 -> { System.out.println(user1.toString()); }); }运行结果如下3、分页+关联查询 @Test public void test5() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> users = userQueryService.queryAll(new User(),pageable,"测试角色"); System.out.println("总数据条数:"+users.getTotalElements()); System.out.println("总页数:"+users.getTotalPages()); System.out.println("当前页数:"+users.getNumber()); users.forEach(user1 -> { System.out.println(user1.toString()); }); } }通过角色的名称查询用户,运行结果如下
-
JPA入门,Spring Boot 整合 JPA 操作数据库 简单了解Jpa(java Persistence API,java持久化 api),它定义了对象关系映射(ORM)以及实体对象持久化的标准接口。在 Spring boot中 JPA 是依靠 Hibernate才得以实现对的,Hibernate 在 3.2 版本中对 JPA 的实现有了完全的支持。Spring Boot 整合 JPA 可使开发者用极简的代码实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!添加依赖#这里添加 Jpa 和 Mysql 的依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>开发Jpa编写实体类定义用户实体类 User//@Entity 表明这个是一个实体类 @Entity //指定表名 @Table(name = "user") public class User { /** * 表明这个字段是主键,并且ID是自增的 */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** * 这样则表示该属性,在数据库中的名称是 username,并且使唯一的且不能为空的 */ @Column(name = "username",unique = true,nullable = false) private String username; private Integer age; private String sex; //get set略 }配置文件说明Spring Boot 配置文件 application.yml 内容如下server: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/jpa username: root password: 123456 jpa: hibernate: #注入方式 ddl-auto: update naming: #Hibernate 命名策略,这里修改下 physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl properties: hibernate: #数据库方言 dialect: org.hibernate.dialect.MySQL5InnoDBDialectddl-auto属性说明常用属性: 自动创建|更新|验证数据库表结构。 **create:** 每次启动时都会删除上一次的生成的表,然后根据你的实体类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。 **create-drop :** 每次加载 hibernate 时根据 model 类生成表,但是 sessionFactory 一关闭,表就自动删除。 **update:** 最常用的属性,第一次加载启动时根据实体类会自动建立起表的结构(前提是先建立好数据库),以后以后再次启动时会根据实体类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。 **validate :** 每次应用启动时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。这里我们使用 update,让应用启动时自动给我们生成 User 表基础操作1、编写 UserRepo 继承 JpaRepositoryimport me.zhengjie.domain.User; import org.springframework.data.jpa.repository.JpaRepository; public interface UserRepo extends JpaRepository<User,Long> { }2、使用默认方法在 test 目录中,新建 UserTests @RunWith(SpringRunner.class) @SpringBootTest public class UserTests { @Autowired private UserRepo userRepo; @Test public void test1() { User user=new User(); //查询全部 List<User> userList = userRepo.findAll(); //根据ID查询 Optional<User> userOptional = userRepo.findById(1L); //保存,成功后会返回成功后的结果 user = userRepo.save(user); //删除 userRepo.delete(user); //根据ID删除 userRepo.deleteById(1L); //计数 Long count = userRepo.count(); //验证是否存在 Boolean b = userRepo.existsById(1l); } } 自定义简单查询自定义的简单查询就是根据方法名来自动生成 SQL,主要的语法是 findXXBy, readAXXBy, queryXXBy, countXXBy, getXXBy 后面跟属性名称:public interface UserRepo extends JpaRepository<User,Long> { /** * 根据 username 查询 * @param username * @return */ User findByUsername(String username); /** * 根据 username 和 age 查询 * @param username * @param age * @return */ User findByUsernameAndAge(String username,Integer age); }具体的关键字,使用方法和生产成 SQL 如下表所示KeywordSampleJPQL snippetAndfindByLastnameAndFirstname… where x.lastname = ?1 and x.firstname = ?2OrfindByLastnameOrFirstname… where x.lastname = ?1 or x.firstname = ?2Is,EqualsfindByFirstnameIs,findByFirstnameEquals… where x.firstname = ?1BetweenfindByStartDateBetween… where x.startDate between ?1 and ?2LessThanfindByAgeLessThan… where x.age < ?1LessThanEqualfindByAgeLessThanEqual… where x.age ⇐ ?1GreaterThanfindByAgeGreaterThan… where x.age > ?1GreaterThanEqualfindByAgeGreaterThanEqual… where x.age >= ?1AfterfindByStartDateAfter… where x.startDate > ?1BeforefindByStartDateBefore… where x.startDate < ?1IsNullfindByAgeIsNull… where x.age is nullIsNotNull,NotNullfindByAge(Is)NotNull… where x.age not nullLikefindByFirstnameLike… where x.firstname like ?1NotLikefindByFirstnameNotLike… where x.firstname not like ?1StartingWithfindByFirstnameStartingWith… where x.firstname like ?1 (parameter bound with appended %)EndingWithfindByFirstnameEndingWith… where x.firstname like ?1 (parameter bound with prepended %)ContainingfindByFirstnameContaining… where x.firstname like ?1 (parameter bound wrapped in %)OrderByfindByAgeOrderByLastnameDesc… where x.age = ?1 order by x.lastname descNotfindByLastnameNot… where x.lastname <> ?1InfindByAgeIn(Collection ages)… where x.age in ?1NotInfindByAgeNotIn(Collection age)… where x.age not in ?1TRUEfindByActiveTrue()… where x.active = trueFALSEfindByActiveFalse()… where x.active = falseIgnoreCasefindByFirstnameIgnoreCase… where UPPER(x.firstame) = UPPER(?1)分页查询Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable);Pageable 是 spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则@Test public void test2() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> list = userRepo.findAll(pageable); }限制查询有时候我们只需要查询前N个元素 /** * 限制查询 */ List<User> queryFirstByAge(Integer age); List<User> queryFirst10ByAge(Integer age);自定义SQL如果项目中由于某些原因 Jpa 自带的已经满足不了我们的需求了,这个时候我们就可以自定义的 SQL 来查询,只需要在 SQL 的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上 @Modifying /** * 自定义SQL,nativeQuery = true,表明使用原生sql */ @Modifying @Query(value = "update User u set u.userName = ?1 where u.id = ?2",nativeQuery = true) void modifyUsernameById(String userName, Long id); @Modifying @Query(value = "delete from User where id = ?1",nativeQuery = true) void deleteByUserId(Long id); @Query(value = "select u from User u where u.id = ?1",nativeQuery = true) User findByUserId(Long id);本文主要讲解了 Jpa 的一些简单的操作,下篇文章将讲解 Jpa 如何使用 Specification 实现复杂的查询,如多表查询,模糊查询,日期的查询等
-
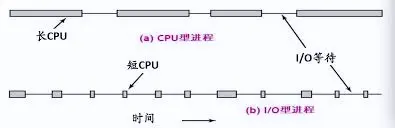
Java开发,配置线程池时线程数应该怎么设置 合理的设置线程数能有效提高 CPU 的利用率,设置线程数又得区分任务是CPU密集型还是 IO密集型。解释CPU密集型 就是需要大量进行计算任务的线程,如:计算1+2+3+...、计算圆周率、视频解码等,这种任务本身不太需要访问I/O设备,CPU的使用率高;IO密集型 就是任务运行时大部分的时间都是CPU在等I/O (硬盘/内存) 的读/写操作,如:查询数据库、文件传输、网络请求等,CPU的使用率不高。根据经验1、CPU密集型:线程数少一点,推荐:CPU内核数 + 1 2、IO密集型:线程数多一些,推荐:CPU内核数 * 2 3、混合型:可以将CPU密集和IO密集的操作分成两个线程池去执行即可!PS:这种方式可能会被面试官找茬根据计算公式根据《Java并发编程实战》书中的计算线程数的公式Ncpu = CPU的数量 Ucpu = 目标CPU的使用率, 0 <= Ucpu <= 1 W/C = 等待时间与计算时间的比率 为保持处理器达到期望的使用率,最优的池的大小等于: Nthreads = Ncpu x Ucpu x (1 + W/C)实战假如在一个请求中,计算操作需要10ms,DB操作需要100ms,对于一台2个CPU的服务器,设置多少合适假设我们需要CPU的使用率达到100%,那么套入公式:`2 x 1 x (1 + 100/10) = 22`但是实际开发中,可能有各种因素的影响,因此就需要我们在这个结果的基础上进行压力测试,最终得到一个完美的线程数量最后补个网图,解释了CPU密集型、IO密集型
-
-
解决 ssh: connect to host github.com port 22: Connection timed out 问题引入当我在国内 Linux 机器上安装好 Git 环境后,将 github 代码克隆到 Linux 服务器出现了如下问题[root@ydyno ~]# git clone git@github.com:elunez/**.git 正克隆到 '**'... ssh: connect to host github.com port 22: Connection timed out fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.解决方法进入 ~/.ssh 查看是否缺少 config 配置文件,如果缺少该配置文件那么使用如下命令创建# 创建并写入文件数据 vi ~/.ssh/config # 写入如下数据,User 填入注册时的邮箱 Host github.com User xxxxx@xx.com Hostname ssh.github.com PreferredAuthentications publickey IdentityFile ~/.ssh/id_rsa Port 443修改文件权限sudo chmod 600 config再次 clone 发现已经没问题了[root@ydyno ~]# git clone git@github.com:elunez/**.git 正克隆到 '**'... remote: Enumerating objects: 14, done. remote: Counting objects: 100% (6/6), done. remote: Compressing objects: 100% (6/6), done. ^C收对象中: 35% (5/14), 2.67 MiB | 544.00 KiB/s 参考:https://docs.github.com/en/authentication/troubleshooting-ssh/using-ssh-over-the-https-port#enabling-ssh-connections-over-https
-
记 Debian 11 机器安装 python3 和 pip 的过程 由于搭建 gh-proxy Github加速工具需要用到 python 环境,因此记录下在 Debian10/11 机器安装 python3 和 pip 的过程准备工作apt update开始安装## 安装 python apt install python3.9 apt install python3.9-dev apt install python3.9-venv # 安装 pip wget https://bootstrap.pypa.io/get-pip.py python3.9 get-pip.py # 建立连接 ln -s /usr/bin/python3.9 /usr/local/bin/python3 ln -s /usr/local/bin/pip /usr/local/bin/pip3成品 Github 加速站点:https://proxy.zyun.vip/
-
vue 中 input 限制只能输入数字,允许正数与负数 vue 的 input 中, 限制只能输入正数与负数,完整代码如下:<template> <el-input v-model="number" @input="onlyNbr1" @change="onlyNbr2"/> </template> <script> data() { return { number: null } }, methods: { onlyNbr1(ipt) { let data = String(ipt) const char = data.charAt(0) // 先把非数字的都替换掉 data = data.replace(/[^\d]/g, '') // 如果第一位是负号,则允许添加 if (char === '-') { data = '-' + data } this.number = data }, onlyNbr2() { const data = String(this.number) // 如果只有一个负数,那么替换为 null console.log(data === '-') if (data === '-') { this.number = null } } } }如果有更好的实现方式,欢迎评论讨论。
-
-
教你使用开源 Azure 开机面板管理 Azure 账号 提取到 Microsoft Azure 的 API 参数 后我们就可以使用Azure 开机面板管理账号的开机、关机、换IP等操作。使用 Azure 面板方式管理 Azure 账号,能降低 Azure 对账号的风控。该方式适合对 Azure 官网操作不熟的用户,也适合有多个 Azure 账号需要管理的用户。项目地址:https://github.com/elunez/azure-manager安装 Docker应用依赖 Docker 环境,使用一键脚步安装 Dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun && systemctl start docker && systemctl enable docker创建应用使用下面的脚本创建应用docker run -itd --name az \ --restart always \ -p 8888:8888 \ dqjdda/azure-manager:latestARM机器用户请使用docker run -itd --name az \ --restart always \ -p 8888:8888 \ dqjdda/azure-manager:arm初始化管理员账号与密码docker exec -it az flask admin 用户名 密码访问 http://IP:8888 进入管理页面登陆后添加需要管理的账号邮箱:用于多账号区分,可填写你注册azure的邮箱密码:appId|password|tenant|subscriptions创建 VPS添加完账号后,点击账号右侧管理 -> 新增添加后,等待几分钟后刷新页面,就能看到创建好的虚拟机了。虚拟机默认 ssh 端口为 22默认账号与密码:账号:defaultuser 密码:Thisis.yourpassword1重置系统使用下面脚本可以一键重置为纯净的 debian 系统注意替换脚本中的 自定义密码sudo -i curl -fLO https://raw.githubusercontent.com/bohanyang/debi/master/debi.sh && chmod a+rx debi.sh && ./debi.sh --cdn --network-console --ethx --bbr --user root --password 自定义密码 --timezone Asia/Shanghai && shutdown -r now